LinkIt
Introduction
Our world today revolves largely around the internet, especially social media. With the advent of internet giants like Facebook, Twitter, Google, the internet has become a hub for a large part of the human population. Naturally, a large amount of personal data exists within the “secure” databases of these giants. Just how much about a person can be inferred from this treasure trove of personal data on these databases? That is exactly what we decided to figure out with this project.
What is LinkIt?
LinkIt is a project of the Privacy and Secirity in Online Social Media Course that aims to create awareness about the consequences of accepting requests from unknown people on online social media platforms.

Aim
We attempt to analyze the statistics of a group of people across multiple social networks like Facebook, Instagram, and Twitter to gauge the following
- Emotional band
- Popularity
- Level of activity and active hours
- What their broad interests are (based on certain predefined categories)
- Closest friends
- A network of friends locations (heatmap)
- Political inclinations, Tolerance, Humor, and other such traits
- Possible family (if not directly stated by the user)
Parameters
- Likes - What type of content do you generally appreciate?
- Comments - What is your response to the content you see?
- Connections - Your closest friends/family may give an indication of who to impersonate when phishing you.
- Active Hours - When you are the most active and likely to visit links without checking the sender's address
- Captions - How you display yourself to the rest of the world.
Approach
To begin with, we set our target group to be our batchmates in college. While obviously constrained by time and resources, a small target group(roughly 200 students) where we know every person would give us a better perspective and help us make better judgments about our methods, which could then be extended to a general populace.
We wrote our own Selenium based scraper for Facebook and Instagram data.
We did the following steps
We did the following steps
- Data collection - For every target user that has made the required information public, we downloaded all posts, likes, comments, images, and friend lists and stored it in a database.
- Once we had the data collected, for each user, we created a profile by analyzing their data according to the points mentioned above.
- Once the processed data was ready, we created a web-based GUI to access the information easily and visualize it well.
Data Collection
- Facebook - The Graph API provided by Facebook is very limited and hence we had to resort to web scraping. Using selenium as a backend for the scraper, we built a tool that would iterate through a list of profile links and acquire the required data such as likes, reactions, comments, relevant people and post creation times.
- Twitter - The Twitter API is fairly straightforward and gives access to all the data we required i.e. tweet text, number of likes, retweets, tweet posting times.
- Instagram - Instagram also required a scraper similar to Facebook.
Profile Creation
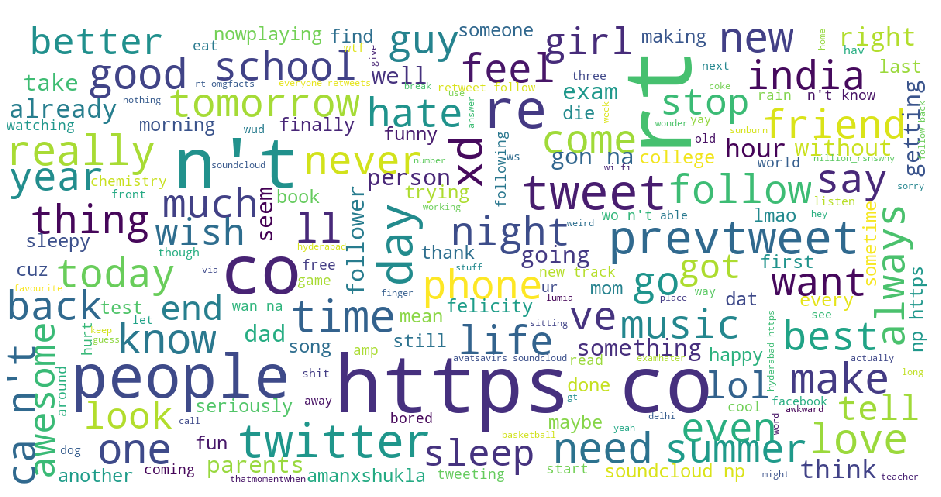
- Based on the content of tweets, posts or comments, we made word clouds for each user to get a high-level view of their most frequently used vocabulary.
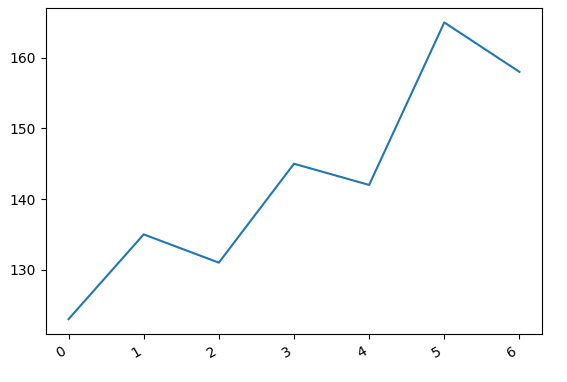
- Based on post creation times, we built graphs to depict their activity. This was done for a day-wise graph as well as a yearly graph.
- We also built a relations graph which depicts the strength of the connection between two individuals, both belonging to our target group. This was done based on their reactions to each others post’s, mentions etc.
This is a word cloud based on the content of a user’s posts.
This is a graph denoting the daily activity of a user over the years. (0 - Sunday)
A network graph of Aniruddha's (kitewarrior4) and Aaron's (arn197) Instagram accounts

Challenges
- Not every network provides an easy-to-use API (such as Facebook) and it can be quite cumbersome and borderline illegal to build tools to circumvent these limitations.
- The task of linking accounts of the same person on different networks was done manually, which was easy given the small size of our target group. We would have to figure out ways to automate this task if we ever extend this project to a larger test group.
Takeaway
The biggest point to be noted is that everyone should be careful about their privacy settings and more importantly, how much information they give out to giants like Facebook and Google. In the end, it's a personal choice. Sure, no company would, ethically and logically speaking, use this data for malicious reasons. However, be aware that they are capable of such actions.








Comments
Post a Comment